Makine öğrenimi bir veri kümesini modele dönüştürmek için en uygun algoritmayı kullanma becerisidir.
Bu makalede kavramsal olarak yanlış anlaşılan makine öğrenimi ve derin öğrenmeyi temel terimlerle açıklamaya çalışmak ve aralarındaki ilişkiyi ortaya koymak vardır. Makale içeriğini tümdengelimle ifade edersem derin öğrenme makine öğrenimi içinde bulunan alt bir daldır şeklinde şimdilik söyleyebiliriz.
Nedir makine öğrenme algoritmaları?
Makine öğrenmesi verilerden modeller oluşturmak için bir yöntemler bütünüdür. Makine öğrenimi algoritmaları makine öğrenmesinin bir nevi motorlarıdır, yani bir veri setini modele dönüştüren algoritmalarıdır. Hangi tür algoritmanın en iyi şekilde çalıştığı (denetlenen, denetlenmeyen, sınıflandırma, regresyon, vb.) analiz edilen verinin türüne, mevcut kaynaklara, verilerin niteliğine ve bütün işlemlerin sonunda istenen ne ise bunlara bağlı değişim göstermektedir.
Makine öğrenmesi nasıl çalışır?
Sıradan programlama algoritmaları bilgisayara ne yapacağını basit bir şekilde söyler. Örneğin, sıralama algoritmaları, sıralanmamış verileri, genellikle verilerdeki bir veya daha fazla alanın sayısal veya alfabetik sırası gibi bazı ölçütlere göre sıralanan verilere dönüştürür. Bu işlem çok basit bir şekilde Excel’de ki filtrelerle yapılabilir. Bunun yanında doğrusal regresyon modelleri düz bir çizgi ile, veri arasındaki küçük kareler hatasını en aza indirgemek için matris dönüşümleri uygulayarak sağlar. Bu işlemler eldeki verilerle işlemlerin sonucunu almak için ideal istatistiksel çözümlemelerdir. Doğrusal olmayan modeller için regresyon problemlerini deterministik çözümlerle yani, sistemin gelecekteki durumlarının gelişmesinde rastgelelik bulunmayan sistemlerle çözmek de tercih edilen yöntemler olmazlar. İşte makine öğrenimi algoritmaları doğrusal olmayan regresyondan daha basit, daha doğru sonuçlar veren ve matematik fonksiyonlarıyla uyumlu çıktılar veren yöntemler barındırır. Sıklıkla iki yöntemden bahsetmek mümkündür. Regresyon ve sınıflandırma. Regresyon ile nicel veriler üzerinde (gelir düzeyi, bitki boyu vs.) çıkarımlar yapılırken, sınıflandırma da sayısal olmayan değişkenleri (Kredi onay durumu, cinsiyet, oda sayısı vs) barındırır. Tahmin sorunları (örneğin, yarın borsa paylaşımları için açılış fiyatı ne olacak?), zaman serisi verileri için regresyon sorunlarının bir alt kümesidir. Sınıflandırma problemleri bazen ikili (evet veya hayır) ve çok kategorili problemlere (hayvan türü, sebze türü vs) ayrılır.
Denetimli (supervised)öğrenme ve denetimsiz (unsupervised) öğrenme kavramları
Regresyon ve sınıflandırma algoritmaları aslında denetimli öğrenme şeklinde ifade edilen makine öğrenme modeli içinde yer alır. Bir diğer makine öğrenme algoritması denetimsiz öğrenme de kümeleme algoritmalarının varlığından bahsederiz.
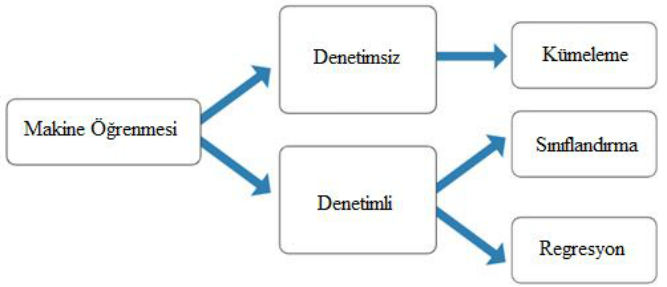
Denetimli öğrenmede bağımsız değişkenlerin işaret ettiği bağımlı değişkenin varlığından bahsettiğimiz, bağımsız değişkenleri eğiterek buradan çıkan sonuca referans veren bir yöntemdir. Örneğin hayvanların resimleriyle beraber isimlerinin bulunduğu bir veri seti düşünelim. Hayvan resmi üzerinde özellikli alanları bağımsız değişken olarak düşündüğümüzde (hayvanın gagası var, kuyruğu var vs. gibi) bu değişkenlerden türeyen gerçek bir sonucu ya da işaret ettiği bir isim verildiğinde, eğitim setine dahil bir hayvan türüne bakarak daha önce hiç görmediği bir resmi tahmin etme becerisi gösterir.
Denetimsiz öğrenmede, algoritma verilerin kendisinin kullanıldığı anlamlı sonuçlar bulmaya çalışır. Sonuç, örneğin, her kümede ilişkilendirilebilecek bir dizi veri noktası kümesi olabilir. Kümeler örtüşmediğinde daha iyi sonuç verir. Birbirine benzer verileri aynı küme altında gruplara ayırır.
Makine öğrenimi için veri temizleme
Çevremize baktığımızda o kadar çok veri var ki, bu verilerin hepsinin işime yaradığını ya da kullanmamız gerektiğini düşünmek hayalciliktir. Temiz ve kullanabilir veri elde etmek için elimizdeki veri setinde uygun bazı işlemler yapmak zorundayız. Örneğin, veri setimizde araştırma yapmak istediğimiz bir değişken altında çok fazla eksik (kayıp) veri varsa, ilgili değişkeni silerek göz ardı edebiliriz. Ancak o değişken bizim için önemliyse, yanındaki değişkenlerle bir korelasyon kurulacaksa, olan veriler üzerinden bu işlemi yapmamız gerekebilir. Bunun için kayıp verilerin çeşitli yöntemlerle doldurulması (ortalama alma, en yakın komşuluk değerlerini kullanma vs.) gerekebilir. Belirgin yazım hatalarını düzeltme ya da eşdeğer cevapları birleştirme de verileri analiz etmede kolaylık sağlayacaktır. Örneğin Atatürk, Mustafa Kemal, Mustafa Kemal Atatürk tek bir kategoride birleştirilmelidir. Araştırmak istediğimiz aralığın dışında veri varsa bunları hariç tutmak gereklidir. Örneğin, İzmir’deki taksi yolculuklarını analiz ediyorsak, İzmir dışında olan verileri analiz dışında tutmamız gerekmektedir. Yapabileceğimiz çok daha fazla şey vardır. Belki de makine öğrenmenin en kapsamlı süreçlerinden birisi budur. Veri setine ne kadar hakim olursak, algoritmaları o kadar kolay uygulayabileceğimizi unutmamız gerekmektedir.
Makine öğrenimi için veri kodlama ve normalleştirme
Özellikle kategorik veriler üzerinde sınıflandırma çalışması yapıyorsak, o veriyi temsil eden etiketlerin sayısal değerlerle kodlanması gerekebilir. Cinsiyet için kadın=1, erkek=2 kodlaması yaptığımızda işlemlerin sayısal değerler üzerinden yapılacağını düşünmemiz gerekir. Bu işleme etiket kodlaması da denebilir. Diğer taraftan sıcak kodlama da denilen, her metin etiketi değerinin ikili değere (1 veya 0) sahip bir sütuna dönüştüğü bir kodlama biçimi de bulunmaktadır. Çoğu makine öğrenme platformu bu işlemleri bizim adımıza yapabilir, yeter ki ne yapmak istediğimize karar verelim.
Sayısal verileri makine öğrenmesinde kullanmak için genellikle verileri normalleştirmemiz gerekir. Aksi takdirde, daha geniş aralıklara sahip değişkenlere sahip oluruz ki bu durum verileri yakınsamakta bize zorluk çıkarabilir. Makine öğrenmesi için verileri normalleştirmenin ve standartlaştırmanın min-maks normalizasyonu, ortalama normalizasyonu, standardizasyonu ve birim uzunluğuna ölçeklenmesi dahil olmak üzere bir çok yolu vardır.
Makine öğreniminde özellik nedir?
İstatistiksel çalışmalarla uzun süredir ilgiliyseniz değişken (bağımlı/bağımsız, nitel/nicel, sürekli/kesikli) kavramına uzak değilsinizdir. Makine öğrenmesinde özellik kavramı, gözlenen bir birimin (bireyin) ölçülebilir bir özelliği ya da karakteristiğidir. “Özellik” kavramı, doğrusal regresyon gibi istatistiksel tekniklerde kullanılan açıklayıcı bir değişkenle ilgilidir. Özellik, sorunu açıklayan minimum bağımsız değişkenler kümesini seçmektir. İki değişken yüksek derecede ilişkiliyse, ya da tek bir özellikte birleştirilmeleri gerekiyorsa farklı bir değişken altında bu işlemler yapılır. Bu birleştirme işleminde de ortaya çıkan yeni değişken yeni özelliklerle karşılık bulur. Örneğin, doğum yılını ölüm yılından çıkardığımızda, yaşam boyu veya ölüm analizi için bağımsız bir değişken elde ederiz ki yeni ve farklı özelliklerle karşımıza gelir.
Yaygın makine öğrenmesi algoritmaları
Doğrusal regresyon ve lojistik regresyondan derin sinir ağlarına ve daha karmaşık düzinelerce makine öğrenme algoritması vardır. Bununla birlikte, en yaygın algoritmalardan bazıları şunlardır:
- Linear regression, en küçük kareler yöntemi(sayısal veriler için)
- Logistic regression (ikili sınıflandırma için)
- Linear discriminant analysis (çok kategorili sınıflandırma için)
- Karar ağaçları (sınıflandırma ve regresyon için)
- Naive Bayes (sınıflandırma ve regresyon için)
- K-En yakın komşuluk, KNN algoritması (sınıflandırma ve regresyon için)
- Vektör nicemlemenin öğrenilmesi – Learning Vector Quantization, LVQ (sınıflandırma ve regresyon için)
- Destek vektör makinası – Support Vector Machines, aka SVM (ikili sınıflandırma için)
- Random Forests, (sınıflandırma ve regresyon için)
- ve dahası…
Yukarıda yazılı algoritmaların dışında yapay sinir ağları ve derin öğrenme algoritmalarının da olması beklenebilir. Ancak burada ifade edilen özel donanıma ve işlem gücüne gerek kalmadan çözümleme yapan algoritmalardır. GPU (ekran kartı) ve işlem gücüne ekstra ihtiyaç duymazlar, görece büyük veri setine sahip değilse. Yapay sinir ağları ve derin öğrenme algoritmalarını daha çok görüntü işleme, konuşma tanıma gibi özellikli konular ve araştırmalar içinde düşünsek daha doğru olabilir.
Makine öğrenmesi algoritmaları için hiper-parametreler
Ne olacağının sistemi tasarlayan kişiye bırakıldığı, veri setine göre farklılık gösteren parametreler hiper-parametre olarak ifade edilir. Örneğin KNN algoritması için k değerinin kaç olacağı ilgili uzman kişi ya da sistemden sorumlu araştırıcı tarafından yürütülür.
Makine öğrenme algoritmaları, tahmin edilen değeri veya sınıfı etkileyen her bağımsız değişken için en iyi ağırlık kümesini bulmak için veriler üzerinde eğitim alır. Algoritmaların kendileri hiper-parametreler adı verilen değişkenlere sahiptir. Hiper-parametreler belirlenen ağırlıklar yerine algoritmanın çalışmasını belirlenen değerlerle kontrol ederler.
En önemli hiper-parametre, en uygun değeri bulmak için denenen ağırlık kümesini bulurken kullanılan adım boyutunu belirleyen öğrenme hızıdır. Öğrenme oranı çok yüksek (overfitting – aşırı öğrenme) ya da çok düşükse (underfitting – eksik öğrenme) öğrenme istendiği ölçüde çözüme kavuşamamış olabilir. Bu yüzden hiper-parametre seçimleri bu anlamda önemlidir.
Belirli algoritmalar, aramalarının şeklini kontrol eden hiper-parametrelere sahiptir. Örneğin, bir Random Forest Sınıflandırıcısı yaprak başına minimum numune, maksimum derinlik, bölünmüş minimum numune, bir yaprak için minimum ağırlık oranı ve yaklaşık 8 tane daha için hiper-parametreye sahiptir. Random Forest algoritmasını giriş düzeyinde okursanız yazılanlar daha anlamlı olacaktır. (bknz. https://medium.com/data-science-tr/makine-%C3%B6%C4%9Frenmesi-dersleri-5-bagging-ve-random-forest-2f803cf21e07)
Hiper-parametre ayarı (tuning)
Birçok makine öğrenmesi platformları (python, R vs) hiper-parametre ayarı yapılmayı olanaklı kılıyor. Temel olarak, sisteme hangi hiper-parametreleri değiştirmek istediğimizi ve hangi metriği optimize etmek istediğimizi söylersek, sistem bu hiper-parametreleri izin verilen sayıda çalışma boyunca otomatik ayarlar. (Google Cloud hiper-parametre ayarı yaparken, TensorFlow uygun metriği çıkarır, bu nedenle belirtmemize gerek kalmaz)
Süpürme hiperparametreleri için üç arama algoritması vardır: Bayes optimizasyonu, grid-search ve random search. Bunların içinde Bayes optimizasyonu en verimli olma eğilimindedir.
Deneyimimiz, birçok hiper-parametre kullanmak yerine, yettiği kadar hiper-parametre kullanımında eldeki verilerimiz ve algoritma seçimimiz için en önemli olanları keşfetmemize yardımcı olacaktır.
Otomatik makine öğrenimi
Makine öğrenmesinde doğru algoritma seçimi yapmanın verilerimiz için en uygun modeli vereceği aşikar. Tabi bunun için tek tek algortima denemesi yapmak kolay bir işlem değildir. Bir de bunu manuel bir düzende yapmak sadece verilerle boğuşmak ve sonunda yılmak gibi bir sonuçla bizi bırakabilir.
Her şeyi denemek pratik değildir, bu yüzden elbette makine öğrenimi aracı sağlayıcıları AutoML sistemlerini kullanmak gerekmektedir. En iyileri, feature engineering algoritmalar ve normalizasyonlar üzerinde taramalarla kendini gösterir. En iyi model veya modellerin hiper-parametre ayarı algoritma seçimi sonrasına bırakılır. Bu durumun AutoML kolay çözümlenen ve bence üzerinde en çok düşünülmesi gereken süreç olduğu bilinmelidir.
Özetle, makine öğrenme algoritmaları makine öğrenme bulmacasının sadece bir parçasıdır. Algoritma seçimine (manuel veya otomatik) ek olarak, optimize ediciler, veri temizleme, özellik seçimi, özellik normalizasyonu ve (isteğe bağlı olarak) hiperparametre ayarlarıyla ilgilenmeniz gerekir.
Tüm bunları ele aldığımızda ve verilerimiz için çalışan bir model oluşturduğumuzda, modeli dağıtmanın ve koşullar değiştikçe güncellemenin zamanı gelmiştir.
Kaynak: Martin Heller,2019 – https://www.infoworld.com/article/3394399/machine-learning-algorithms-explained.html#
Hocam burda bu konuların dışında kalabilir ama sadece tensorflow bilip sklearn kütüphanelerine bulaşmadan da bu alanda sadece derin öğrenme konusuna odaklanıp ilerlemek mümkün müdür ?
mümkündür ancak, istatistiğin, matematiğin ve programlamanın temellerini anlaman kaydıyla. Bu temeller senin bildiğin kütüphanelerle standart işlemler yapmanın ötesine geçirecek ve çözümü sorgulayan bir kimliğe kavuşturacak. Bildiğinin yeterli olmadığını öğreneceksin bu şekilde. İyi çalışmalar
Hocam selamlar makine öğrenmesi algoritmalarından birtanesini FPGA ile gerçeklemek istiyorum hangisini tavsiye edersiniz
Merhaba Hasan
Yapacağın çalışmanın niteliği kullanacağın algoritmayı belirler. Hatta başka parametrelerde vardır. Aşağıdaki kaynaklara göz gezdirmeni öneririm.
Soracağınız birşey olursa, detaylı bilgilendirerek iletişim kanallarından ulaşabilirsin.. kolay gelsin..
http://dspace.yildiz.edu.tr/xmlui/handle/1/8110
https://tez.yok.gov.tr/UlusalTezMerkezi/tezDetay.jsp?id=Tg_3rdPG9H9NtU–C11efA&no=jQzLUbVOwpGBmB1VUicqtQ
Hocam merhaba. Makine öğrenmesi algoritmaları ile borsa hisse senetleri tahmini araştırması yapıyorum. Sizden birkaç konu hakkında bilgi almak istiyorum. Size hiçbir yerden ulaşamadım, twitter’dan takip ettim. Bana geri dönüş sağlarsanız çok sevinirim. İyi çalışmalar.
telegram grubuma üye olursanız direkt erişim sağlayabilirsiniz..
hocam merhabalar, hangi algoritmalar hangi programlarda kullanılıyor hakkında bir yazınız var mı ? Böyle bir yazıya denk gelmedim merak ediyorum.
Cevabım geç olduğu için kusura bakmayın, öyle bir yazı yazmadım ama, hangi algoritmalar hangi problemlerde kullanılır şeklinde bir yazı yazmayı planlıyorum. Sizin dediğiniz birçok programlama dili hemen hemen tüm algoritmaları kullanır.
Hocam merhaba, Microsoft’un Excel üzerindeki makine öğrenmesi uzantısı olan Azure Machine Learning’te Text Sentiment Analysis programı ile Duygu Analizi yapıyorum. Program sonuçları gayet başarılı şekilde Pozitif, Negatif ve Nötr olarak sınıflandırıyor. Fakat Sınıflandırma Algoritması olarak Lojistik Regresyon mu, Destek Vektör Makineleri mi veya başka bir şeye göre mi sınıflandırdığını bir türlü anlayamadım. Ona göre makalem de “Sınıflandırma Başarım Ölçütü” olarak “Doğruluk”, “Kesinlik”, “F” skoru vereceğim. Burada manuel olarak Sınıflandırma Başarısını hesaplarsam sizce hangi algoritmaya göre hesaplandığını belirteyim ? . “Azure Machine Learning Otomatik Sınıflandırma Başarısı” demem hatalı mı olur. Videoda burada bahsettiğim yöntem gösteriliyor. Yardımı olursanız çok memnun olurum, Teşekkürler 🙂 https://www.youtube.com/watch?v=D7TjyKGY9J0
Azure makine öğrenmesinde duygu analizi yaparken hangisini kullandığını bilemem ama, senin yazdıklarınla beraber diğer algoritmaları da kullanabildiğini söyleyebilirim. Acaba kullandıkları içinde en iyi performansı vereni sonuç olarak vermiş olabilir. Duygu analizi ile çözümlenmiş çalışmaları incelersen orada en iyi sonucu veren algoritmayı yazabilirsin ama çok da bilimsel olmaz.. Kolay gelsin
Hocam analizi yaparken hem gözlenen hem gerçekleşen şekilde programın sınıflandırmasının yanı sıra kendi gözlemimi de Label olarak sınıflandırdım. Daha sonra Sınıflandırma başarısında Accuracy, Precision, Recall ve F skorunu manuel olarak hesapladım. Sınıflandırma başarısında sadece bu programın başarısını hesapladım.
Eğer veri setine bakarak hangi algoritmaya en yakın olduğunu tespit etmede güçlük yaşıyorsan, makalende bu bilgi eksik olarak belirtilebilir veya bu konuda bir tahmin yapılabilir.
Örneğin, “Azure Machine Learning kullanılarak oluşturulan modelin sınıflandırma algoritması bilinmemektedir” veya “Modelin sınıflandırma algoritması tahminen Lojistik Regresyon veya Destek Vektör Makinesi olabilir” gibi bir ifade kullanılabilir.
Ancak bu tür tahminlerin doğruluğu konusunda emin olunamayacağı için, bu bilgilerin doğruluğu konusunda da dikkatli olunmalıdır. Hakem sürecinde eleştiri alabilir bu durum.. İfadeni seçerek ve güçlü kaynaklarla beslersen sorun yaşamayabilirsin..
Kolay gelsin
m.